近日,人工智能领域的新星Grok-3在发布仅仅三天后,就卷入了一场关于评估作弊的风波。这场风波的导火索,是OpenAI应用主管对Grok团队在评估过程中的行为提出的质疑。
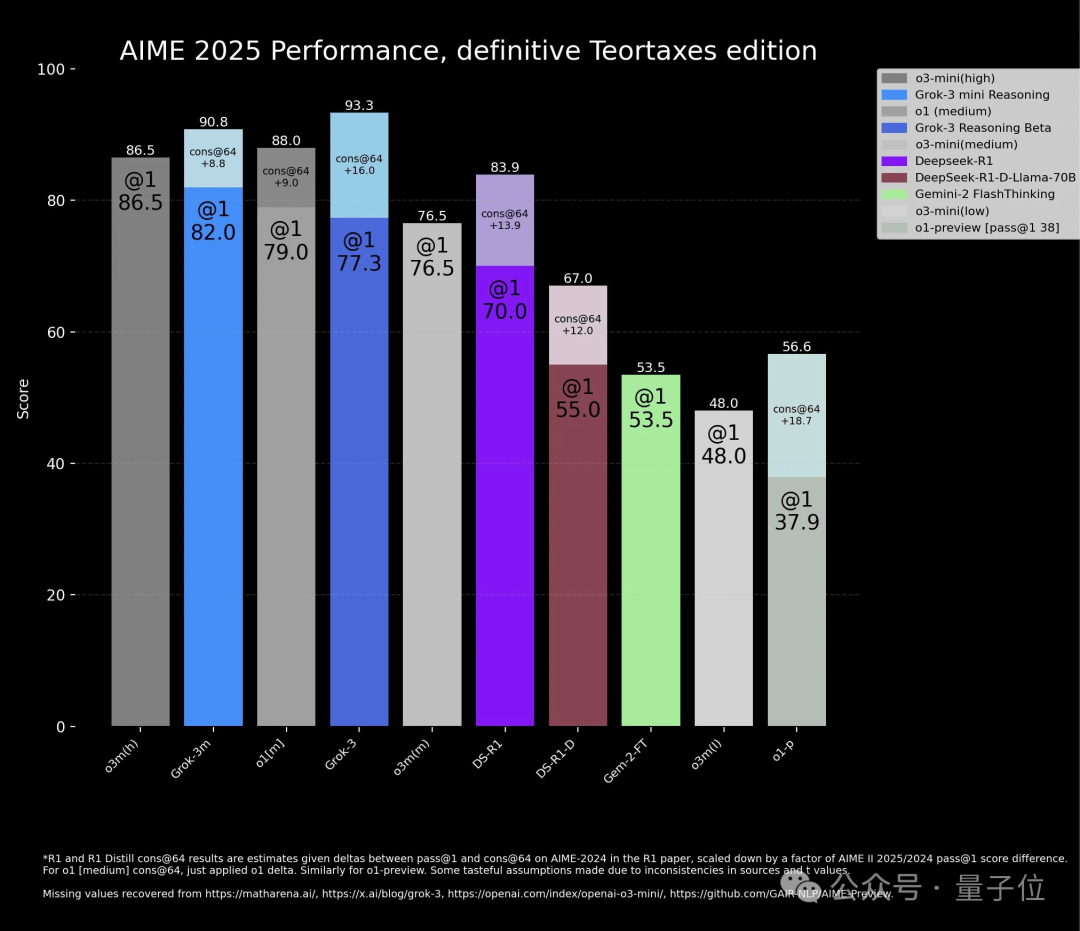
在Grok-3的官方博客中,一张AIME 2025的评估图表引起了广泛关注。图表显示,Grok-3的两个新版本模型在性能上均超越了OpenAI的o3-mini高配版。然而,细心的观察者发现,Grok-3两个模型的柱状图中,有一部分颜色较浅,这部分正是OpenAI所指责的“作弊”之处。
浅色部分代表了Grok-3模型在Con@64上的成绩,即模型在生成64个答案后,取出现频率最高的回答作为最终结果。而与之对比的o3-mini、o1、DeepSeek-R1、Gemini-2 Flash Thinking等模型,在评估中并未采用这一方式。
OpenAI的研究员Aidan McLaughlin对此表示强烈不满,他认为Grok团队的这种做法极具误导性,让人误以为浅色部分是通过推理实现的成绩。他还指出,如果真是如此,那么Grok-3的推理能力其实只与o1相当,而OpenAI的o3-mini仍然保持着9个月的领先地位。

不过,也有观点认为,这场风波的根源在于评估方法的不统一。采用cons@64的评估方式,确实能让模型在某些情况下表现出更好的性能,但这并不意味着其他模型就应该被不公平地排除在外。如果其他模型只是尝试了一次回答,那么与Grok-3的对比就显得不够公平。
为了证明这一点,有AI博主列出了相关数据,显示在单次回答上,o3-mini的表现更为出色。同时,o3-mini的博客中也采用了类似的评估方式,这进一步加剧了这场风波的复杂性。
Grok团队在发布时的说法也被认为具有误导性。当被问及评估图中的浅色部分时,官方解释称这些模型可以推理、可以思考,并暗示通过花费更多时间让模型解决同一个问题,可以获得更好的性能。然而,这种解释被OpenAI的研究员视为对推理能力的误导性描述。
尽管这场风波给Grok-3的声誉带来了一定影响,但不可否认的是,Grok团队在人工智能领域仍然有着值得关注的成就。例如,Grok-3在短短一个月内就完成了基于CoT的后训练,并展现出了强大的性能。同时,xAI也在以行业内最快的速度扩展预训练计算能力,为未来的发展奠定了坚实基础。
Grok-3的发布还激发了开发者们的创新热情。有人利用Grok-3开发出了小游戏,展示了其在娱乐领域的潜力。例如,一位在微软深度参与Windows系统开发的大佬Dave Plummer,就用Grok-3复刻了经典的打砖块游戏,并展示了如何通过简单的提示词让模型生成游戏代码。

这场风波虽然给Grok-3带来了一定的争议,但也再次证明了人工智能领域的竞争激烈和技术的快速发展。随着技术的不断进步和应用场景的不断拓展,相信未来会有更多的人工智能产品涌现出来,为人类的生活带来更多便利和惊喜。