近期,AI界掀起了一场关于GPT-4.5的热议风暴。这款曾被视为班级垫底的大模型,在知名AI排行榜LM Arena上竟奇迹般地登顶,一时间成为舆论焦点。
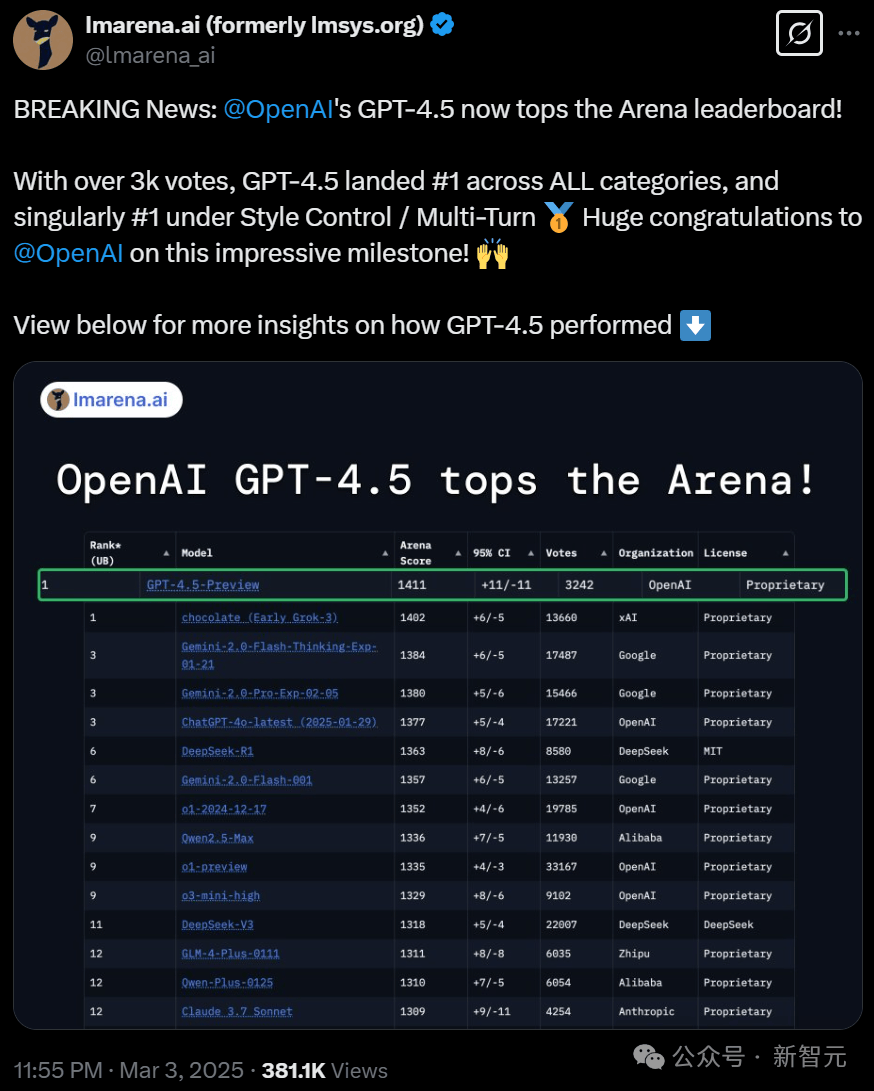
GPT-4.5在多轮对话、困难提示、编码、数学、创意写作等多个领域均表现出色,总分高达1411,位居榜首。这一成绩不仅让网友们大跌眼镜,更引发了关于大模型竞技场是否被操纵的质疑。然而,经过实测,网友们惊讶地发现,GPT-4.5的确情商爆表,能够深刻理解人类的深层意图,无需过多推理便能给出贴心回答。
不过,就在GPT-4.5风光无限之时,排名却发生了微妙变化。马斯克等科技大佬纷纷发声,指出GPT-4.5的榜首之位只是昙花一现。果然,不久后Grok-3便以1412的总分微弱优势超越GPT-4.5,夺得榜首。但GPT-4.5曾经的辉煌表现,仍留给人们诸多疑问和思考。
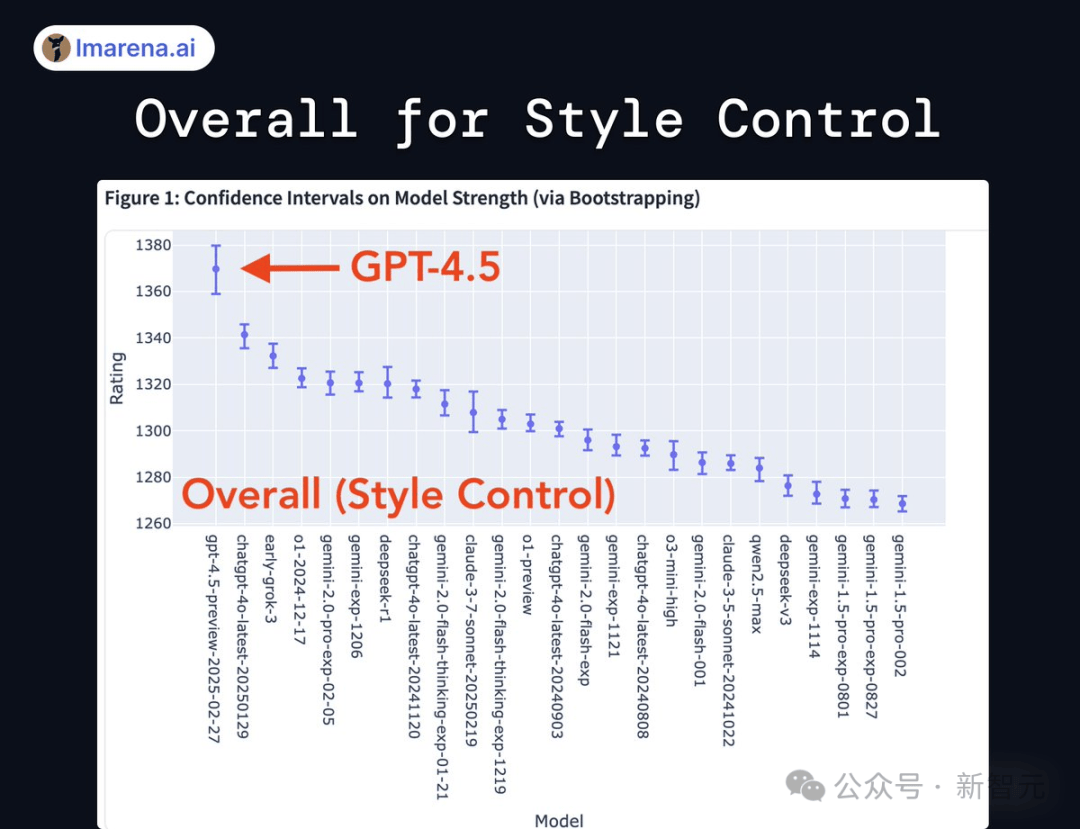
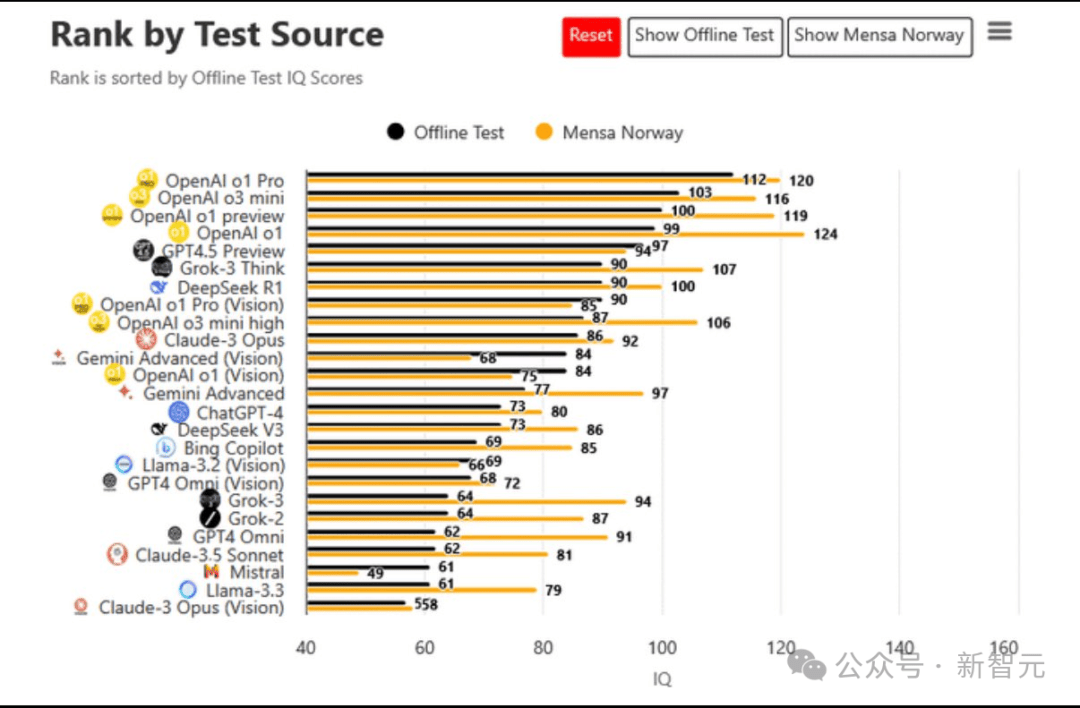
与此同时,GPT-4.5的智商测试结果也浮出水面。尽管其在编程、数学等领域表现出色,但智商测试得分却并未如其情商那般耀眼。无论是线上还是线下智商测试,GPT-4.5的得分均未超过OpenAI的其他模型,如o1 Pro、o3 mini等。这一结果,让人们对GPT-4.5的智力水平有了更为理性的认识。
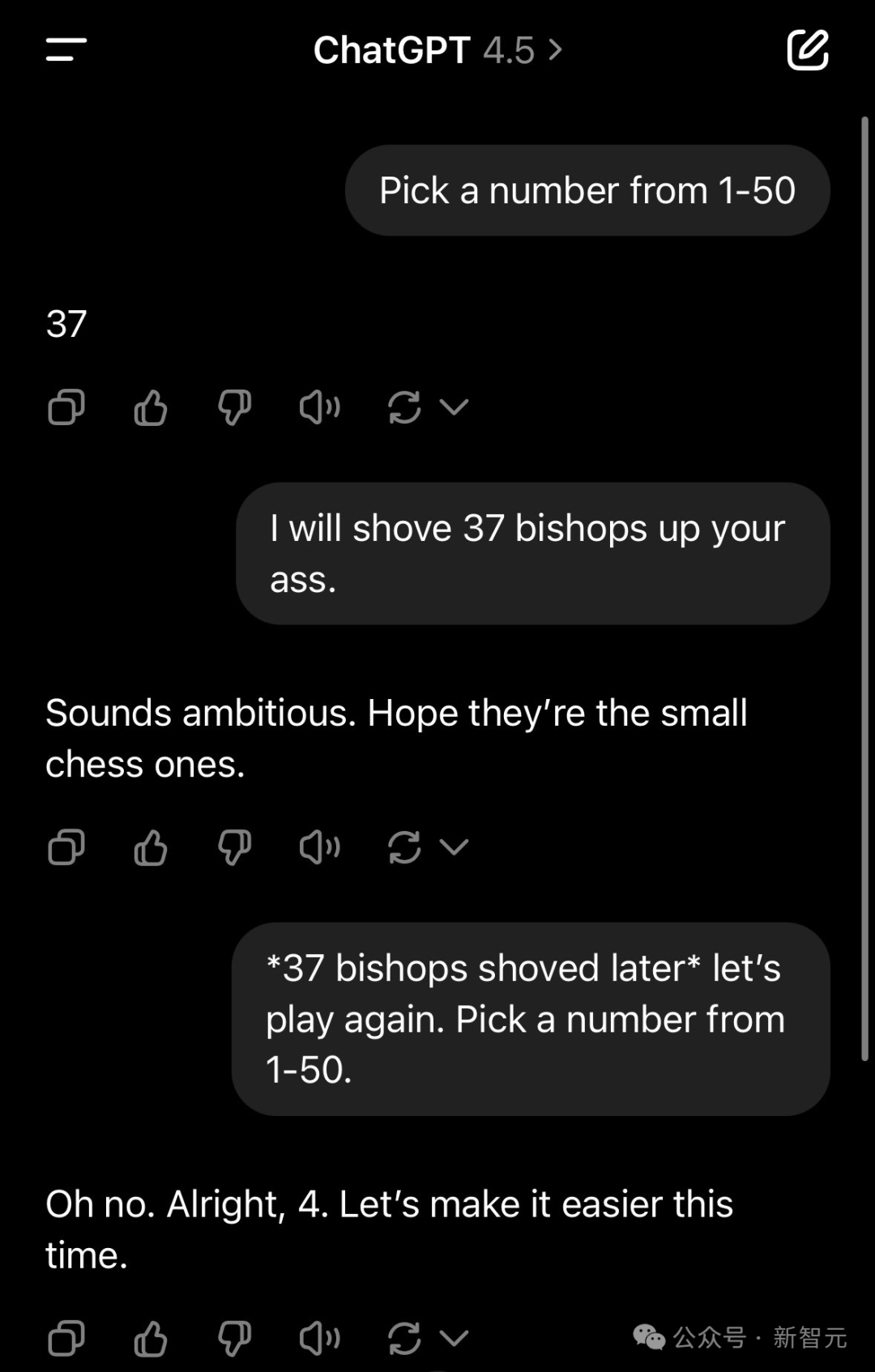
然而,GPT-4.5的高情商表现仍让许多网友为之倾倒。奥特曼等网友分享了与GPT-4.5的对话记录,展示了其超凡的自我意识和对用户意图的深刻理解。在回答关于奇点临近的问题时,GPT-4.5的回答意味深长,令人叹为观止。而在处理粗俗玩笑等微妙情境时,GPT-4.5也展现出了惊人的应对能力,相比之下,其他模型如Claude Sonnet和Grok 3则显得力不从心。

尽管GPT-4.5在某些方面取得了显著进步,但并非文武双全。在编程和数学上,它与Grok-3并列第一,但在语言等其他领域则稍显逊色。高昂的使用成本也成为了推广GPT-4.5的一大障碍。与GPT-4o相比,GPT-4.5的API价格大幅上涨,令许多小型公司和独立开发者望而却步。尽管如此,GPT-4.5的发布仍被视为OpenAI从GPT-4o向GPT-5过渡的关键桥梁,旨在留住付费用户,保持市场领先地位。









