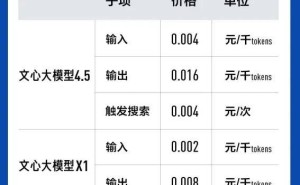
DeepSeek公司近日正式揭晓,其明星产品DeepSeek V3模型已成功迭代至新版本——DeepSeek-V3-0324。用户只需访问DeepSeek的官方平台,无论是网站、应用还是小程序,皆可通过简单操作体验这一升级,具体为在对话模式下关闭深度思考功能,而API接口操作保持不变。
尽管此次更新被定义为小版本迭代,但用户反馈显示,新版模型在性能上实现了显著提升。特别是在前端开发、数学逻辑推导以及语境理解等核心领域,DeepSeek V3-0324展现出了卓越的表现。据透露,V3模型在训练过程中融入了DeepSeek-R1模型所运用的强化学习技术,这一策略显著增强了模型在推理任务中的能力。

在HTML等前端代码生成方面,新版V3模型生成的代码不仅功能强大,而且在视觉呈现上也更加精致,富有设计感。在中文写作领域,新版模型在R1版本的基础上进一步优化了创作能力,特别是在中长篇文本的创作上,内容质量显著提升,为用户带来了更为优质的写作体验。
在联网搜索场景下,新版V3模型在处理报告生成类指令时,能够生成内容更为详尽、准确,且排版清晰美观的报告。该模型在工具调用、角色扮演以及问答互动等功能上也实现了不同程度的提升,为用户提供了更加多元化、便捷的服务。
DeepSeek官方指出,DeepSeek-V3-0324与之前的DeepSeek-V3版本在基础模型架构上保持一致,主要对后训练方法进行了优化。在私有化部署方面,用户只需更新checkpoint和tokenizer_config.json文件(涉及工具调用相关调整)即可完成升级。据悉,该模型的参数规模约为660亿,开源版本支持的最大上下文长度为128K(网页端、App和API提供64K上下文),满足了广大用户的需求。
与DeepSeek-R1保持一致,此次DeepSeek开源仓库(含模型权重)也采用了MIT License授权,为用户提供了极大的灵活性和自由度。用户可以通过模型输出或模型蒸馏等方式训练其他模型,进一步推动了人工智能技术的创新与发展。