阿里巴巴于本周一震撼发布并宣布开源其通义千问3.0(Qwen3)系列模型,该系列模型在数学、编程等多个领域展现出与DeepSeek相媲美的卓越性能。相较于其他主流模型,Qwen3在部署成本上实现了显著降低,引起了业界的广泛关注。
Qwen3系列模型的一大亮点在于其无缝集成了两种思考模式,支持多达119种语言,为Agent调用提供了极大的便利。这一创新设计使得Qwen3能够根据任务需求灵活调整“思考”程度,既能够高效处理简单请求,又能在面对复杂问题时展现出强大的推理能力。
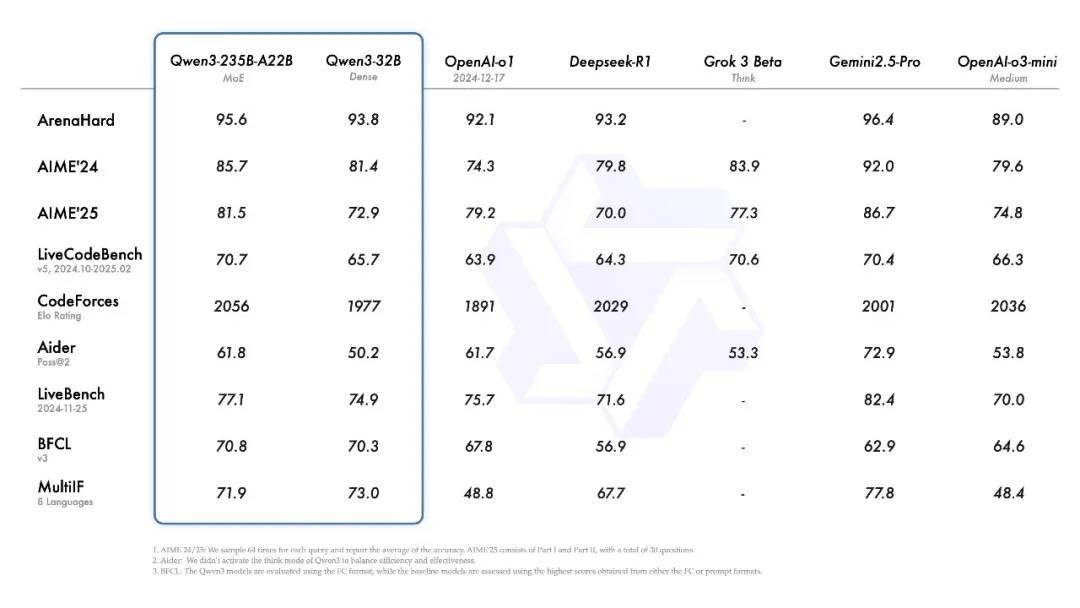
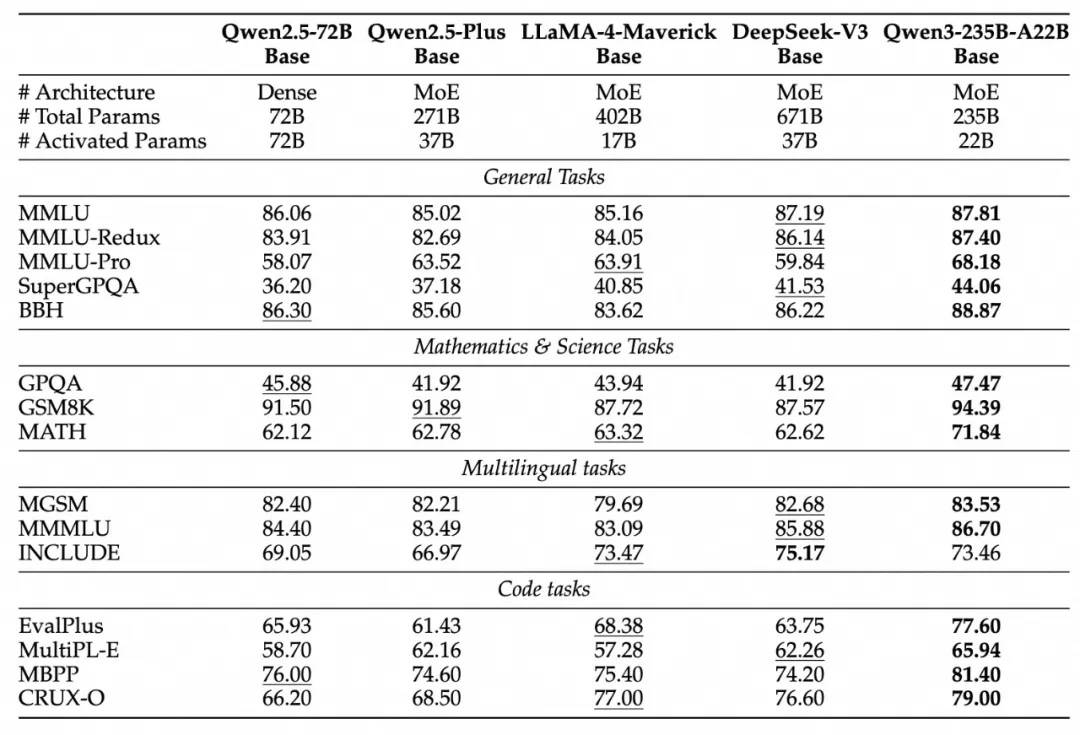
据悉,Qwen3系列包括两个专家混合(MoE)模型和六个其他模型。旗舰模型Qwen3-235B-A22B在代码、数学、通用能力等基准测试中,与DeepSeek-R1、OpenAI的o1等顶级模型相比,展现出了极高的竞争力。特别是被称为“专家混合”模型的Qwen3-30B-A3B,其激活参数数量仅为QwQ-32B的10%,但性能却更胜一筹,甚至小模型Qwen3-4B也能与Qwen2.5-72B-Instruct相媲美。
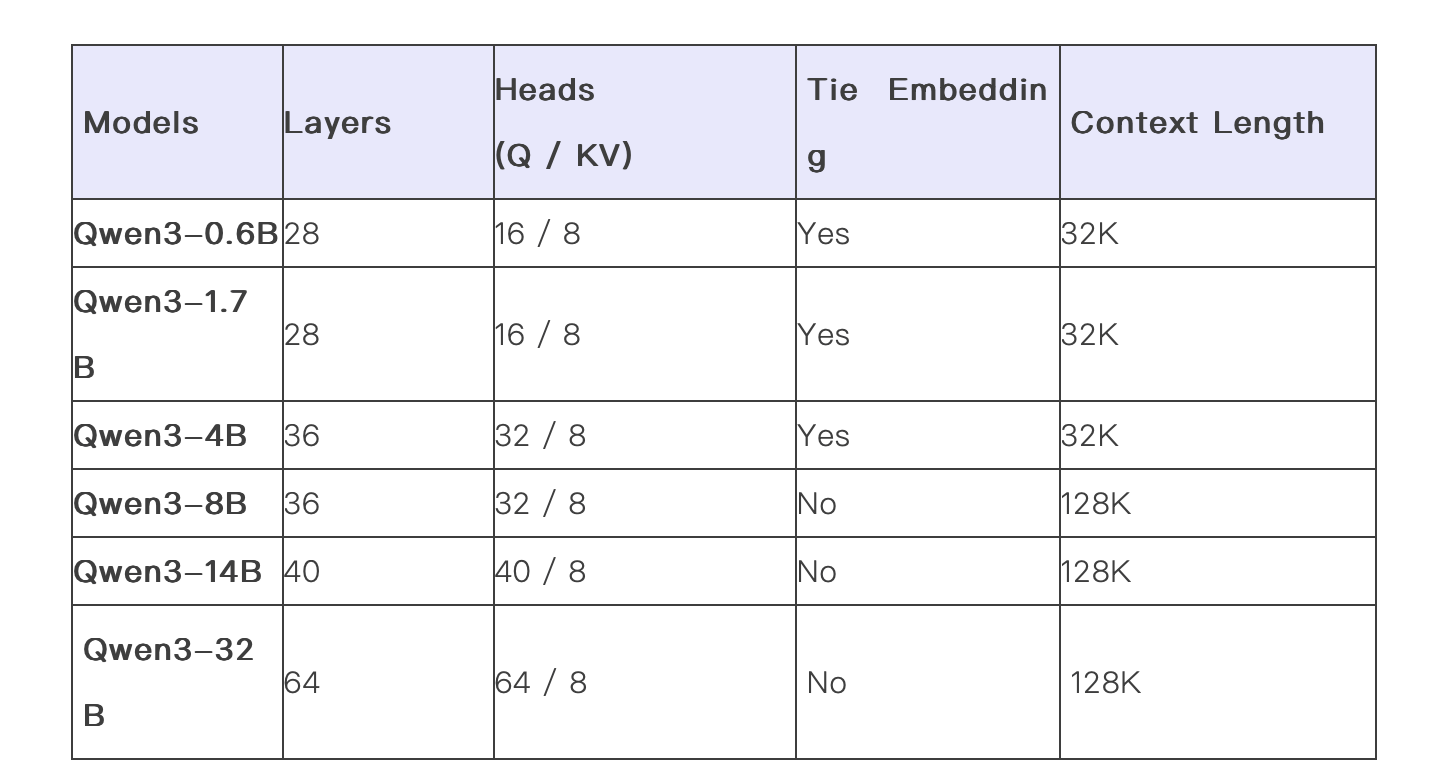
阿里巴巴还慷慨开源了两个MoE模型的权重,包括拥有2350多亿总参数和220多亿激活参数的Qwen3-235B-A22B,以及约300亿总参数和30亿激活参数的小型MoE模型Qwen3-30B-A3B。六个Dense模型也已开源,均在Apache 2.0许可下,为开发者提供了丰富的选择。
Qwen3系列模型不仅在性能上表现出色,其设计也极具创新性。作为“混合型”模型,Qwen3能够灵活切换“思考模式”和“非思考模式”,以适应不同任务的需求。这种灵活性使得用户能够根据具体任务控制模型的“思考”程度,从而在成本效益和推理质量之间实现更优的平衡。
在训练数据方面,Qwen3系列模型基于近36万亿个token进行训练,数据量是Qwen2.5的两倍。训练数据涵盖了教材、问答对、代码片段等多种内容,确保了模型的广泛适用性和准确性。Qwen3的预训练过程分为三个阶段,通过不断增加知识密集型数据和高质量的长上下文数据,逐步提升了模型的语言技能和通用知识。
Qwen3的发布在开源社区引起了强烈反响。网友们纷纷表示,Qwen3的性能令人惊叹,特别是在高维张量运算等方面的表现更是让人印象深刻。有网友称赞道:“这简直像魔法一样!”开源AI的支持者更是激动不已,认为Qwen3的开源将极大地推动AI领域的发展。