近年来,人工智能在游戏领域的卓越表现已不再令人惊讶。
回顾往昔,2018年《星际争霸》的AI挑战赛汇聚了各路高手,各展所长;次年,《王者荣耀》的AI“绝悟”在世界冠军杯表演赛中击败了五位现役职业选手,令人瞩目;而到了2022年,《暗区突围》更是推出了全球首个能语音指挥的AI队友F.A.C.U.L.,将竞技类游戏的体验推向了新的高度。
这些AI队友不仅懂得配合指挥,不抢资源,甚至还能讲冷笑话,为玩家提供了满满的情绪价值。然而,它们都属于“单游戏智能体”,专为特定游戏训练,且依赖于海量的数据支持。
即便是谷歌推出的多游戏智能体Transformer,虽然能够玩转41款雅达利游戏,但同样离不开大量预先学习的数据。简而言之,这些AI都需要模仿人类,通过“学习攻略”来维持其游戏智能。

但近期,加州大学圣地亚哥分校的Hao AI实验室进行了一项别开生面的AI推理能力测试。他们选取了Gemini 2.5 Pro、Claude 3.7 Sonnet、Llama-4 Maverick以及OpenAI o1四个AI模型,在没有任何预先训练的情况下,直接让它们挑战《逆转裁判》这款游戏。
这意味着这些AI需要自主理解游戏画面、剧情与机制,并推动游戏进程,如同初次接触游戏的新玩家一般。测试结果显示,Llama-4 Maverick在游戏初期便被淘汰,而Gemini 2.5 Pro和Claude 3.7 Sonnet进入了第二章《逆转姐妹》,OpenAI o1更是打到了第二集结尾,表现相当出色。

Hao AI实验室之所以选择《逆转裁判》作为测试游戏,主要有三个目的:一是检验AI的长语境推理能力,要求AI能够交叉引用先前的对话和证据,发现矛盾;二是测试视觉理解能力,观察AI能否准确识别并反驳虚假陈述的图像;三是考察动态决策能力,要求AI在有限的试错次数内做出正确的选择,如何时施压、出示证据或隐瞒。
测试结果表明,这些AI仅凭自身的推理能力,便展现出了接近人类的理解和处理问题能力。例如,它们能够理解证词中的漏洞,并自主决定打开菜单、出示证物。
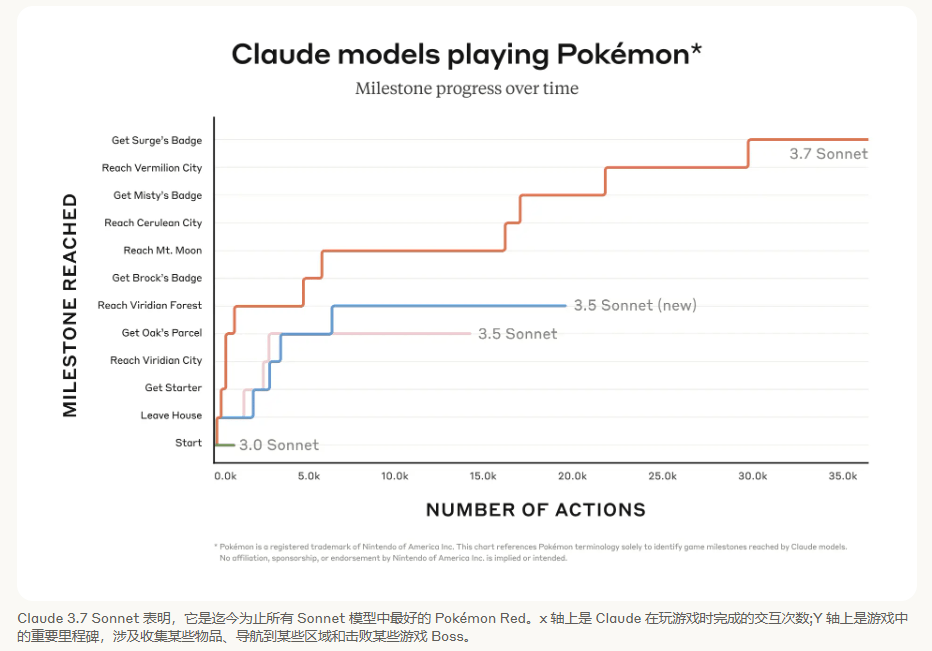
在五个月前进行的《精灵宝可梦 红/绿》测试中,Claude 3.0 Sonnet还无法走出真新镇。而经过迭代后的Claude 3.7 Sonnet,如今已能在游戏中完成超过30000次互动,并自主击败三位道馆馆长。由此可见,OpenAI通关《逆转裁判》也只是时间问题。