在人工智能领域,一项关于强化学习的新发现正引发广泛讨论。华盛顿大学的一组博士生最近的研究表明,在使用Qwen模型进行可验证奖励强化学习(RLVR)时,即使奖励信号是错误的,模型的性能也能得到显著提升,这一发现颠覆了以往对RLVR的认知。
传统上,RLVR被认为是通过正确的奖励信号来优化语言模型的推理能力。然而,这项研究却提出了一个反直觉的观点:错误的奖励信号或许也能发挥意想不到的作用。为了验证这一假设,研究团队设计了一系列实验,通过逐步简化的奖励函数来替代标准的真实奖励。

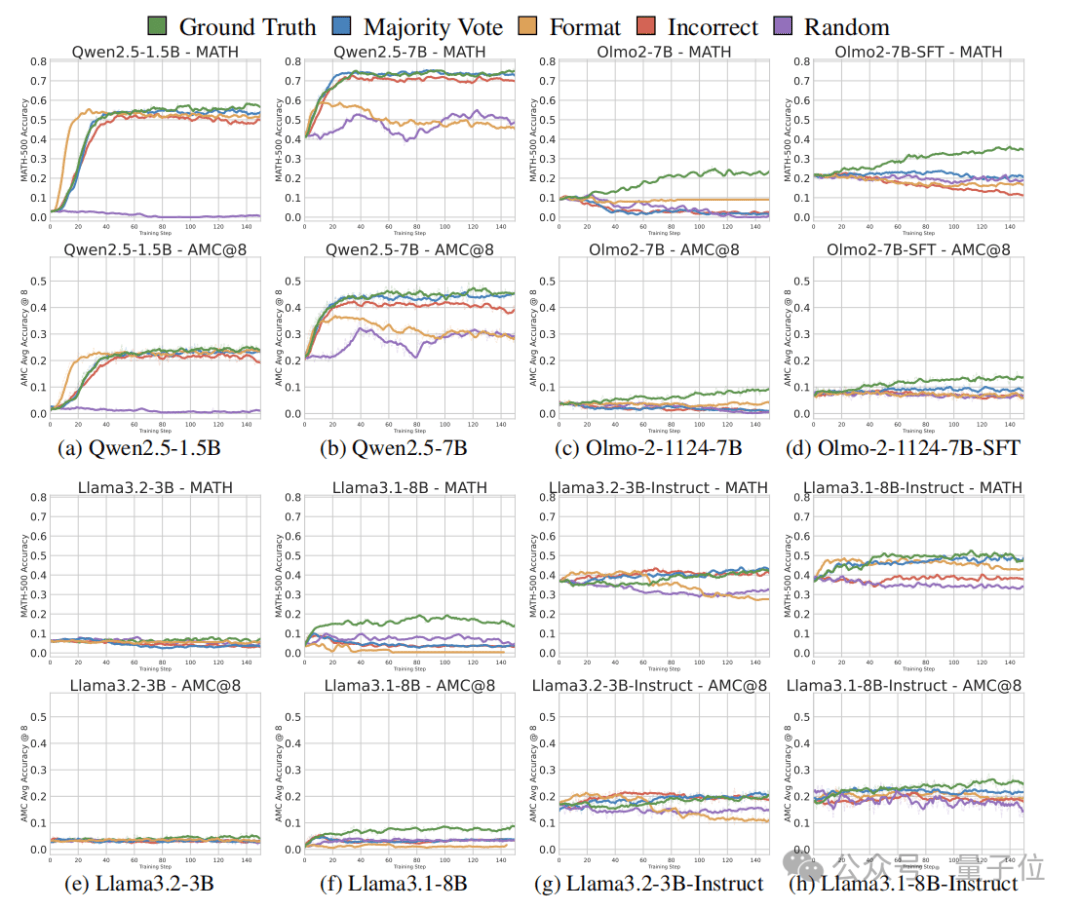
实验结果显示,无论是真实奖励、多数投票奖励、格式奖励、随机奖励还是错误奖励,都能在短期内显著提升Qwen模型在数学推理任务上的性能。尤其值得注意的是,即使是完全错误的奖励或随机奖励,与基于真实标签的RLVR相比,性能提升的幅度也相差无几。例如,在MATH500基准测试上,使用错误标签奖励进行训练,模型性能提升了24.6%,而基于真实答案的RLVR提升幅度为28.8%,随机奖励也能带来21.4%的性能提升。
这一发现引发了研究团队对Qwen模型与其他模型之间差异的深入探索。通过分析推理轨迹,他们发现,Qwen模型在预训练期间学习到了特定的推理策略,即频繁生成Python代码来辅助思考过程。这种代码推理行为与答案准确率高度正相关,并且在RLVR训练后,代码推理频率迅速提升。而其他模型,如Llama、Qwen2.5-1.5B以及OLMo2-7B,则没有表现出这种代码推理行为,因此也无法从虚假奖励中获益。

研究团队进一步指出,这种奇怪的增益现象可能与Qwen模型的特定结构和预训练方式有关。他们推测,GRPO方法的裁剪偏差可能在某种程度上诱导了随机奖励生成有益的训练信号,从而增加了代码推理行为,实现了性能提升。这一发现不仅揭示了RLVR的新机制,也为未来的模型优化提供了新的思路。
这项研究在学术界和工业界都引起了广泛关注。许多研究人员表示,这一发现将对RLVR的研究方向产生深远影响,尤其是那些围绕Qwen模型精心构造奖励函数的研究员们,可能需要重新审视自己的研究方法。同时,这一发现也强调了预训练数据和模型结构在强化学习中的重要性。

研究团队还提醒业界,现有的以Qwen为中心的RLVR研究可能需要在非Qwen模型上做进一步验证。不要只盯着单一模型做数值提升的工作,因为那可能意义并不大。相反,应该更关注模型的推理过程和预训练数据的多样性,以探索更多潜在的性能提升途径。
尽管这一发现引发了许多争议和讨论,但它无疑为人工智能领域带来了新的思考和启示。随着技术的不断发展,我们有理由相信,未来将有更多关于RLVR和其他强化学习技术的创新发现,推动人工智能向更高层次迈进。