在AI技术日新月异的今天,GitHub上惊现一款由腾讯开源的创新项目——HunyuanVideo-Avatar,瞬间在AI圈内掀起了波澜。
这款开源的视频生成神器,仅需一张图片和一段音频,就能让图片中的人物、动物乃至虚拟形象“栩栩如生”,不仅能开口说话、高歌一曲,还能演绎相声,令人叹为观止。
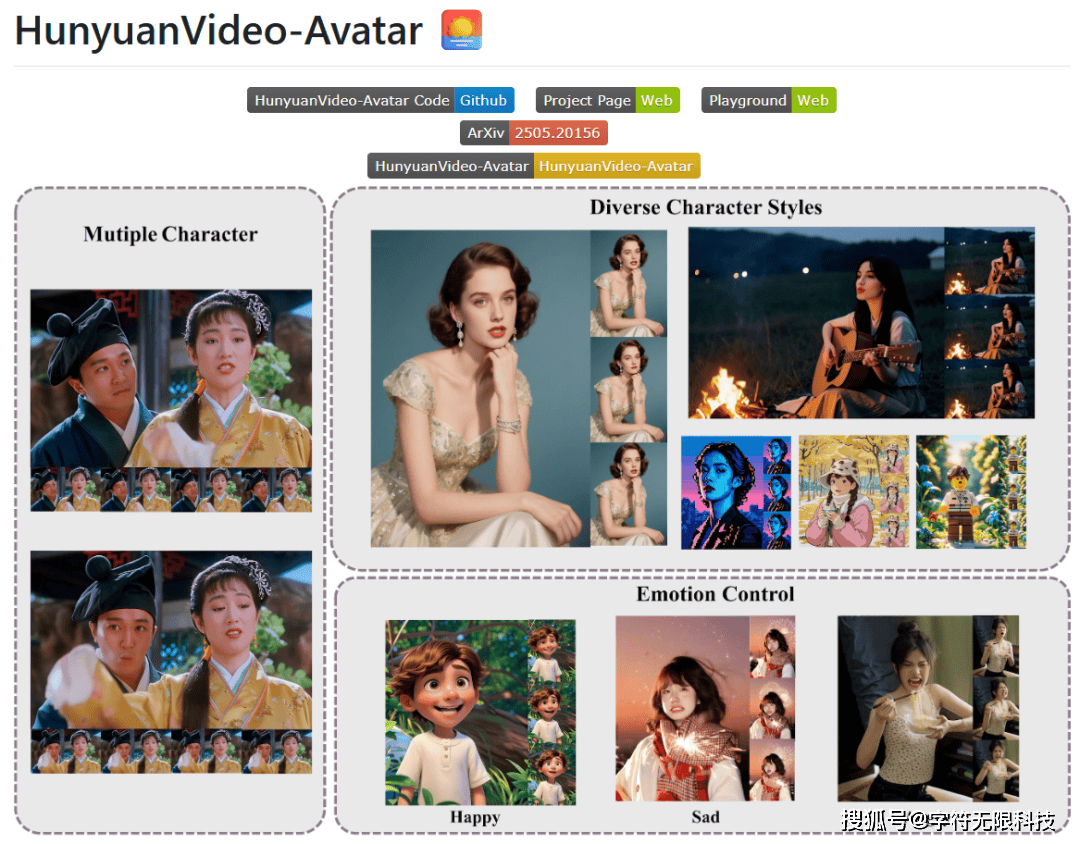
想象一下,爱因斯坦与奥黛丽·赫本通过AI技术“重生”,同台表演相声,这一场景足以让人瞠目结舌。虽然类似工具已屡见不鲜,但腾讯此次开源的HunyuanVideo-Avatar究竟有何独到之处?让我们一同探究。
HunyuanVideo-Avatar宛如一位“数字人导演”,它能够从静态图片中洞悉场景,依据音频中的情感波动,让角色活灵活现地动起来。其奥秘在于三大核心模块:
首先,它摒弃了AI生成的“网红脸”现象。传统模型往往生成千篇一律的角色形象,而HunyuanVideo-Avatar则能将用户的照片精准融入模型,保留原图的所有细节,从衣服褶皱到背景光影,无不栩栩如生。
其次,它赋予AI解读情感的能力。普通语音驱动技术仅能对口型,而HunyuanVideo-Avatar则能从音频中提取情感特征,结合参考图片,生成细腻的表情变化。
最后,它支持多人互动场景。在演示视频中,两个角色的唇形、表情、手势各自独立,互动时的眼神交流更是自然流畅,宛如真人演员。
HunyuanVideo-Avatar的应用场景广泛,为创意实现提供了无限可能:
在电商直播领域,上传商品图片和促销文案,AI主播便能24小时不间断带货,还能根据台词做出夸张表情,吸引用户下单。
音乐平台上,QQ音乐利用该技术让王力宏的AI分身实时“演唱”新歌,酷狗音乐的长音频绘本中,虚拟人则用童声讲述故事,全民K歌则支持用户上传自拍,生成专属MV。
在影视创作方面,导演只需绘制一张场景草图并编写旁白脚本,便能生成分镜动画,极大地提升了创作效率。
那么,运行HunyuanVideo-Avatar需要怎样的硬件配置呢?据官方测试显示,至少需要RTX 3090显卡才能流畅生成720p视频,而A100显卡则能输出电影级画质。