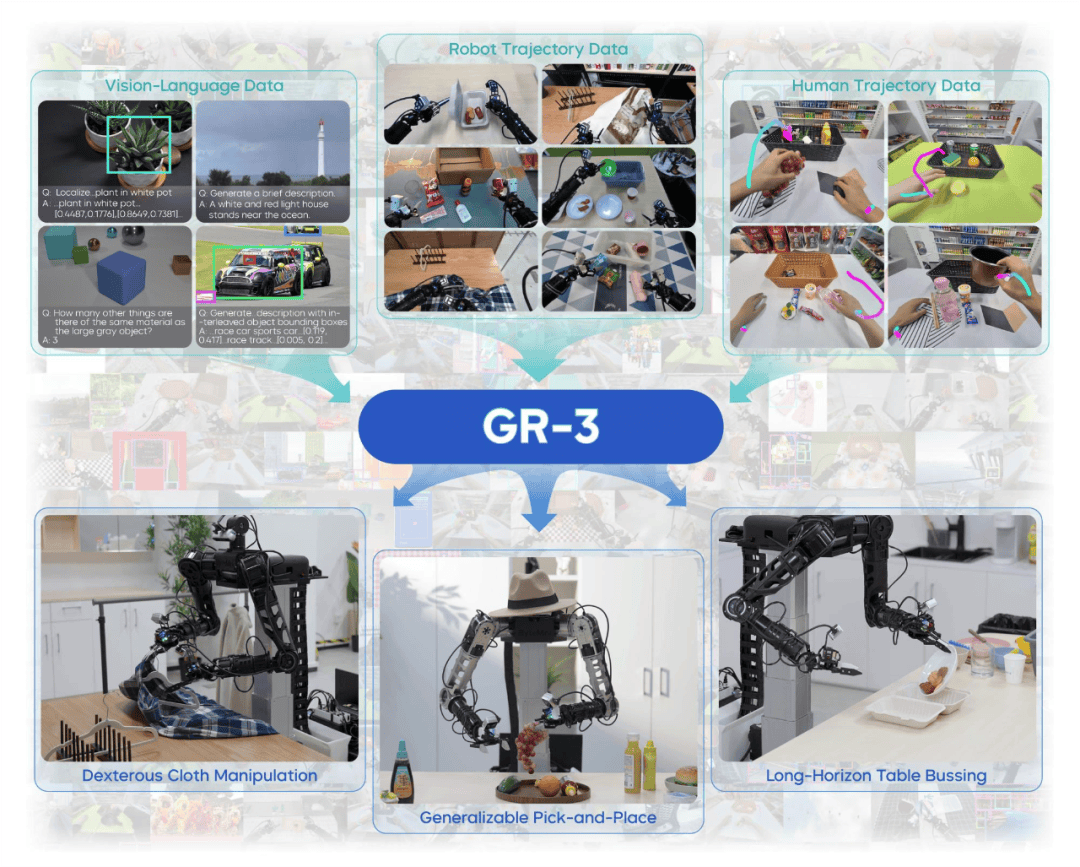
近日,字节跳动旗下的Seed团队宣布了两项重要创新成果:一款名为GR-3的高性能视觉语言动作(VLA)模型,以及一款与之配套的通用双臂移动机器人ByteMini。

GR-3模型以其卓越的泛化能力、长程任务处理能力和对柔性物体的精细操作而备受瞩目。与以往需要大量机器人轨迹数据进行训练的VLA模型不同,GR-3仅需少量人类数据即可实现高效微调,快速适应新任务和识别新物体。这一突破得益于其改进的模型结构和多样的训练方法。
在训练方法上,GR-3不仅利用了遥操作机器人收集的高质量真机数据,还融合了基于VR设备的人类轨迹数据和公开的大规模视觉语言数据。这种多样性数据的融合,使得GR-3在理解和执行复杂指令时更加灵活和准确。
ByteMini机器人则是为GR-3量身定制的“灵活躯体”。这款通用双臂移动机器人具备高灵活性和高可靠性,全身拥有22个自由度,其中无偏置的7个自由度机械臂尤为引人注目。机械臂手腕采用球形设计,能够在狭小空间内完成各种精细操作。
ByteMini在感知层面搭载了多颗摄像头,其中手腕摄像头专注于细节观察,头部摄像头则负责全局监控。在运动控制方面,ByteMini采用了全身运动控制(WBC)系统,结合GR-3模型,能够在真实环境中高效处理复杂任务。
GR-3模型在各类任务中展现出了“心灵”、“手巧”和“泛化好”三大特点。在超长序列的餐桌整理任务中,它能够高鲁棒性、高成功率地完成指令,即使面对多件同类物品也能准确执行。在复杂灵巧的挂衣服任务中,GR-3能够控制双臂协同操作柔性物体,并鲁棒识别不同摆放方式的衣服。
尤为GR-3在物体抓取放置任务中表现出了极强的泛化能力。它能够抓取未见过的物体,并理解包含复杂抽象概念的指令。例如,在挂衣服过程中,GR-3能够泛化到训练数据中未包含的短袖衣物。

在技术层面,GR-3采用了MoT的网络结构,将“视觉-语言模块”和“动作生成模块”结合成一个40亿参数的端到端模型。在数据训练方面,GR-3突破了传统机器人的局限,采用了三合一数据训练法,从遥操作获取的机器人数据、人类VR轨迹数据和公开可用的图文数据中同时学习知识。
Seed团队表示,未来计划进一步扩大GR-3的模型规模和训练数据量,并引入强化学习方法,以进一步提升其泛化能力和突破现有模仿学习的局限。这一创新成果无疑将为机器人在复杂多变的真实场景中的应用开辟新的道路。