美国人工智能初创企业xAI近日宣布了一项雄心勃勃的计划,该公司首席执行官埃隆·马斯克表示,xAI将在未来五年内大规模部署AI GPU,其算力相当于5000万个NVIDIA H100等级的芯片。这一计划不仅在规模上远远超出了当前的AI硬件标准,更在能效方面提出了显著提升的目标。
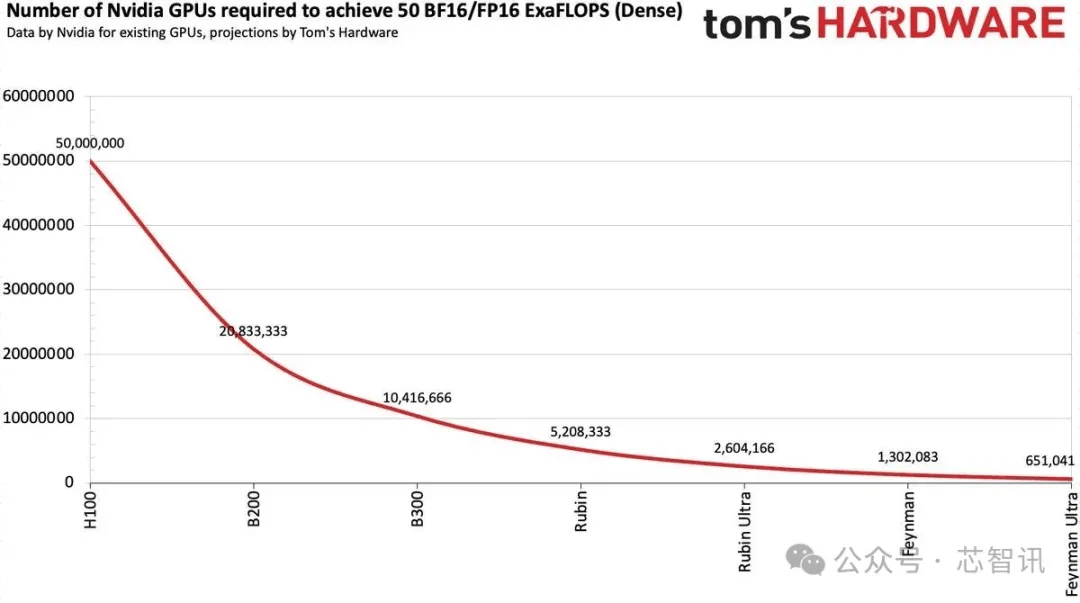
尽管5000万个NVIDIA H100听起来数量庞大,但马斯克强调,这实际上是指“等效算力”。如果xAI在未来五年持续采用最先进的GPU技术,可能仅需不到100万个芯片就能实现这一目标。据估算,到2030年,这5000万台AI加速器将提供高达50个FP16/BF16 ExaFLOPS的算力,专门用于AI训练。根据当前的性能改进趋势,这一目标在未来五年内完全有可能实现。
xAI已经迈出了坚实的步伐,其Colossus 1超级集群已经部署了20万个基于Hopper架构的NVIDIA H100和H200加速器,以及3万个基于Blackwell架构的GB200加速器。马斯克透露,接下来,xAI将构建Colossus 2集群,该集群将由55万个GB200和GB300节点组成,每个节点配备两个GPU,因此整个集群将拥有超过100万个GPU。第一批节点预计将在未来几周内上线。
英伟达和其他AI芯片公司正在加速推出新一代AI加速器,更新节奏已经转变为每年一更新。这种更新模式类似于英特尔过去的Tick-Tock模型,即一年小升级,一年大升级。例如,Blackwell后续将推出Blackwell Ultra,再接下来是Rubin和Rubin Ultra。这种策略确保了每年性能的显著提升,从而推动了长期性能的稳步提高。
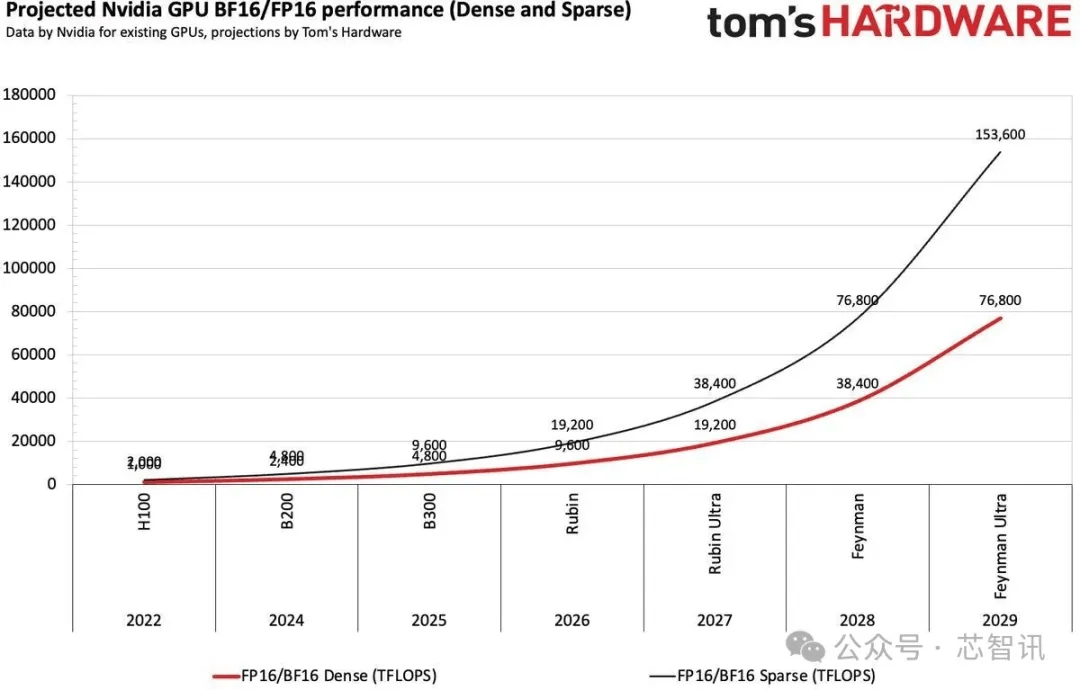
英伟达声称,其Blackwell B200的推理性能比2016年的Pascal P100高出20000倍,提供约20000个FP4 TFLOPS性能,而P100的性能仅为19个FP16 TFLOPS。尽管不是直接比较,但该指标与推理任务密切相关。以每生成一个Token的焦耳数来衡量,Blackwell的能源效率也是Pascal的42500倍。英伟达和其他公司并未随着性能的持续提高而放缓脚步,例如,Blackwell Ultra架构(B300系列)在人工智能推理方面的FP4性能比原始Blackwell GPU高出50%,在人工智能训练方面的BF16和TF32格式性能高出两倍。
根据计算,英伟达H100的FP16/BF16性能相比A100提高了3.2倍,而B200相比H100性能又提高了2.4倍。然而,实际的训练性能不仅取决于新GPU的纯数学性能,还取决于内存带宽、模型大小、并行性(软件优化和互连性能)以及FP32的累积使用。尽管如此,英伟达有望通过每一代新GPU将其训练性能(FP16/BF16格式)提高一倍。
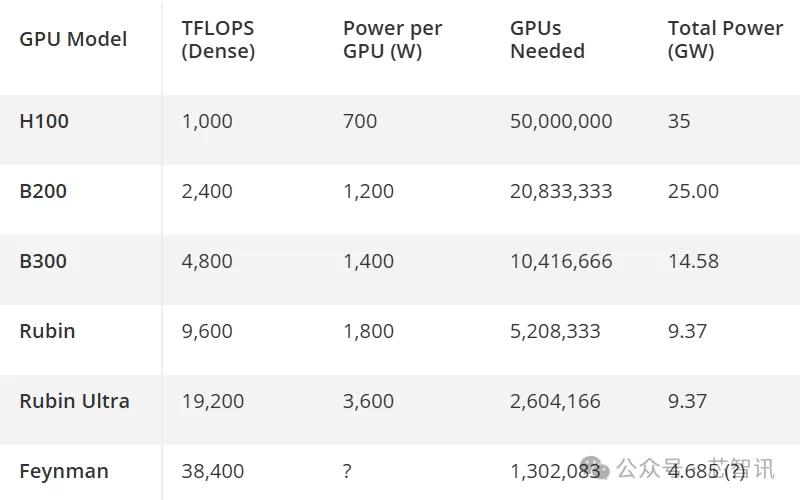
假设英伟达能够通过基于Rubin和下一代Feynman架构的四代后续AI加速器实现上述性能提升,那么在2029年的某个时候,大约需要65万个Feynman Ultra GPU才能达到大约50个BF16/FP16 ExaFLOPS的算力。然而,这一超级AI集群将带来巨大的电力消耗问题。一个H100 AI加速器的功耗大约为700W,因此5000万个处理器将消耗35吉瓦(GW)的电力,相当于35座核电站的典型发电量。即使是Rubin Ultra集群,也需要大约9.37吉瓦的电力。假设Feynman架构使BF16/FP16的每瓦性能比Robin架构翻了一番,一个50 ExaFLOPS集群仍将需要4.685 GW的电力,这对美国当前的能源基础设施提出了严峻挑战。