马斯克旗下人工智能公司 xAI 毫无征兆地扔出一枚“重磅炸弹”——最新模型 Grok 4.1 正式登场,且已全面向所有用户开放。用户可在 Grok 官网、社交平台 X 以及 iOS 和 Android 应用等多个渠道使用这一新模型。

此次更新,Grok 4.1 在 Auto 模式中即刻推送,用户还能在模型选择器中手动挑选。xAI 宣称,该模型在真实世界可用性方面实现了质的飞跃,特别是在创造力、情感互动以及协作交互领域表现卓越。它对用户细微意图的感知更为敏锐,对话更具吸引力,整体人格连贯性更强,同时延续了前代模型强大的智能与可靠性。
为了达成这些提升,xAI 在支撑 Grok 4 的大规模强化学习基础设施基础上,进一步优化了模型的风格、个性、助人性和对齐性。并且,针对不可直接验证的奖励信号,xAI 开发出全新方法,利用前沿的智能体式推理模型作为奖励模型,实现大规模自主评估与输出结果迭代。
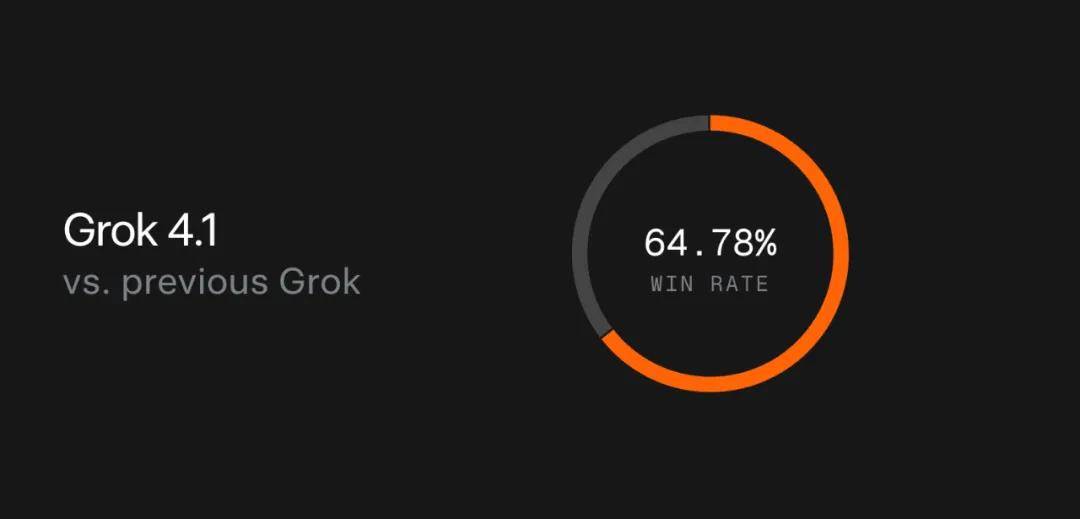
在用户偏好对比评估中,Grok 4.1 展现出强大竞争力,相较于此前线上生产模型,有 64.78% 的概率被用户优先选择。
在通用能力方面,Grok 4.1 在盲测的人类偏好评估中树立了新标杆。在 LMArena 的 Text Arena 排行榜上,其推理模式(代号:quasarflux)以 1483 的 Elo 分数傲居总榜榜首,领先排名最高的非 xAI 模型 31 分。非推理模式(代号:tensor)也毫不逊色,无需使用思维 token 即可即时响应,以 1465 Elo 分数位列第二,即便不启用推理,也超越了其他所有模型在完整推理配置下的表现。与 Grok 4 相比,Grok 4.1 整体表现大幅提升,此前 Grok 4 总排名仅为第 33 名。
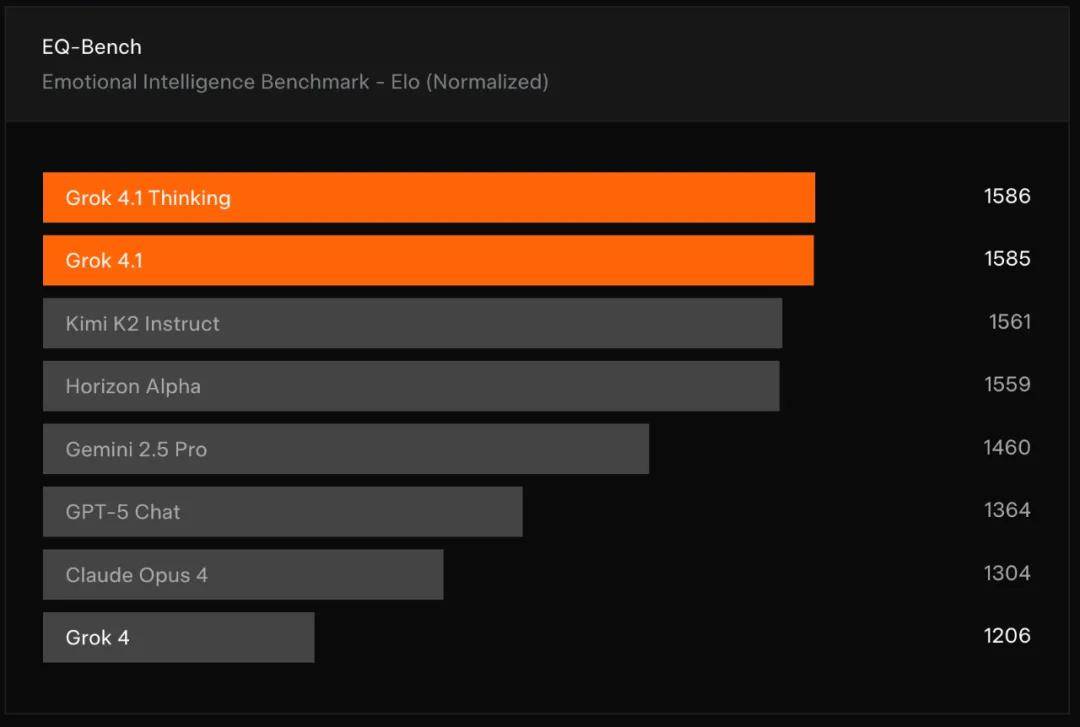
在情感智能领域,xAI 通过 EQ-Bench3 对 Grok 4.1 进行测试。EQ-Bench 是一个由大语言模型评判的测试,用于评估主动情绪智能,涵盖情绪理解、洞察力、同理心以及人际交往技能等方面。测试集包含 45 个具有挑战性的角色扮演场景,多数由预先编写的三轮对话提示组成,通过多项标准验证模型回答质量并计算归一化 Elo 分数。结果显示,Grok 4.1 的推理模式和非推理模式在榜单中占据前两名。
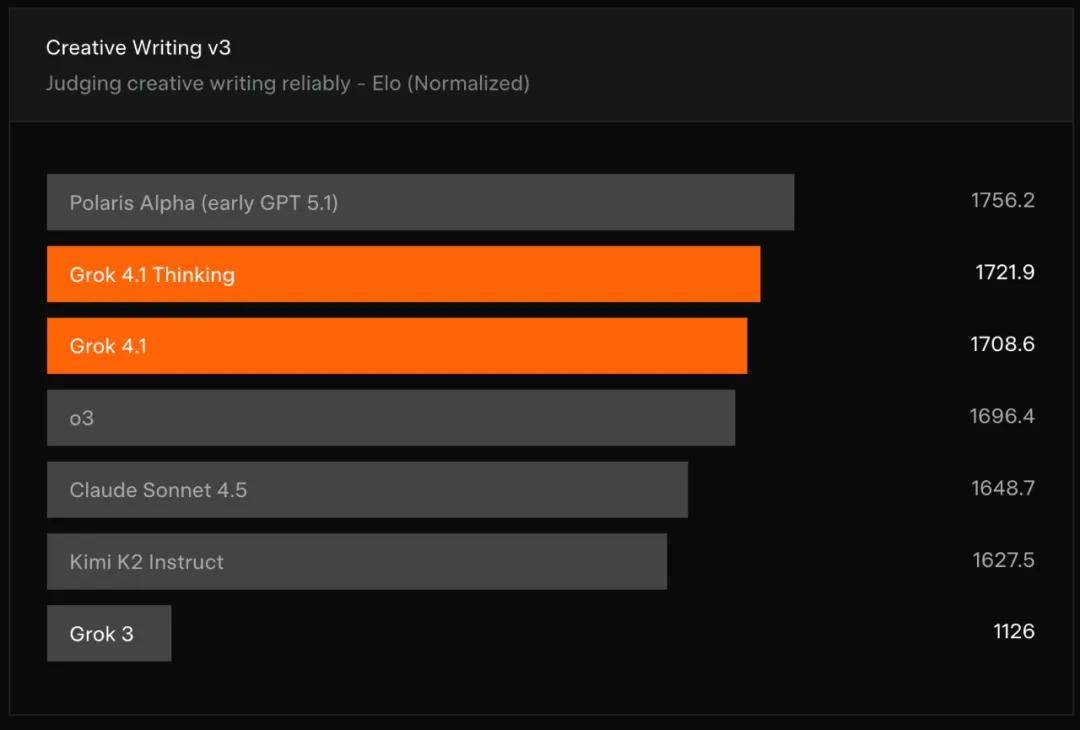
创意写作方面,xAI 在 Creative Writing v3 基准测试上评估了 4.1 系列模型。该基准要求模型针对 32 个不同写作提示生成回答,并进行 3 轮迭代,评分依据评分细则和模型对战的归一化 Elo 分数。结果显示,Grok 4.1 的推理模式和非推理模式分别位居第二和第三名,仅次于早期 GPT 5.1。
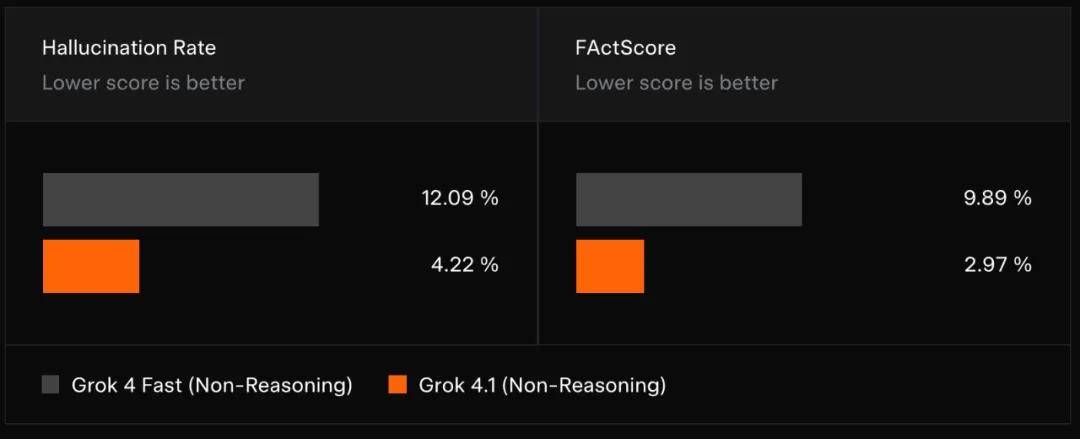
针对配备搜索工具的 Fast(非推理)模型易出现事实性错误的问题,xAI 在 Grok 4.1 的后训练过程中着重降低信息查询类提示的事实幻觉。通过按类别分层抽样评估模型幻觉率,并评测 FActScore(包含 500 个关于不同人物的传记类问题的公共基准测试),观察到生产环境信息查询提示中幻觉率显著下降。