阿里近日宣布开源一款名为Qwen-Image-Layered的全新图像生成模型,该模型首次在行业内实现了类似Photoshop的图层理解与生成能力,标志着视觉大模型技术迈入新阶段。通过创新架构设计,该模型可将图像分解为独立图层,支持近乎零误差的精准编辑,有效解决了传统AI生成图像在一致性方面的核心难题。

传统视觉大模型普遍采用"扁平化"处理方式,将图像视为像素矩阵的简单叠加,导致物体遮挡、空间关系等物理特性难以被准确捕捉。这种技术局限使得AI生成的图像在编辑时往往牵一发而动全身——例如调整画面中某个元素的位置时,背景内容会同步发生不可控变化,严重制约了其在专业设计领域的应用价值。商业广告、UI界面设计等需要高精度控制的场景,至今仍依赖传统设计工具完成最终制作。
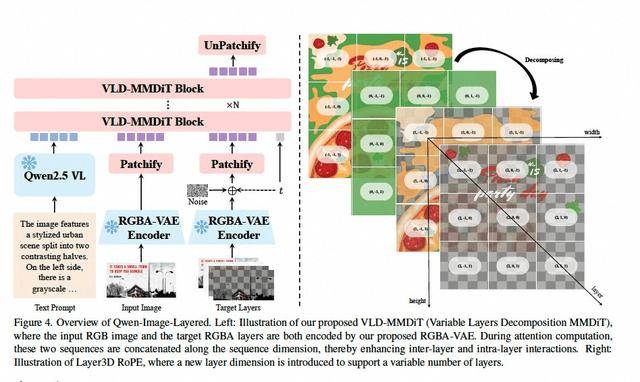
Qwen-Image-Layered通过引入分层处理机制,构建起对三维空间的立体认知。研发团队开发的RGBA-VAE编码技术,在传统RGB色彩模式基础上新增透明度通道(Alpha),使模型具备图层分离能力。配合创新的VLD-MMDiT架构与3D位置编码系统,模型能够自动推断被遮挡区域的背景纹理,实现从"像素预测"到"结构重组"的技术跨越。这种处理方式更接近人类设计师的思维模式,为图像编辑提供了前所未有的操作自由度。
为训练这种空间理解能力,研究团队从海量专业PSD文件中提取图层逻辑数据,构建起包含复杂空间关系的训练样本库。这种数据驱动的方式使模型从诞生之初就掌握分层处理的专业技能,能够精准识别不同图层间的交互关系。测试数据显示,该模型在物体位移、局部重绘等场景中,可保持97%以上的背景一致性,编辑效率较传统方法提升4-6倍。
行业分析师指出,这项突破将重塑数字内容创作流程。设计师可直接在AI生成的分层图像上进行精细化调整,无需手动抠图或重建背景,使创作过程从"开盲盒"式的随机生成转变为可控的模块化组装。影视后期、动画制作等领域可借此技术显著缩短制作周期,降低人力成本。某影视公司技术负责人表示:"该模型让AI真正成为创作伙伴,而非简单的素材生成器。"
目前,Qwen-Image-Layered已通过魔搭社区和HuggingFace平台开源,允许企业和开发者免费商用。这是阿里开源战略的最新成果,其千问系列模型累计开源数量已接近400个,全球下载量突破7亿次,衍生模型超过18万个。在企业级市场,通义大模型以显著优势占据国内市场份额首位,服务客户数量突破100万家,形成覆盖多行业的AI应用生态。
