近日,谷歌在AI领域取得重大突破,推出了其首个全模态图像生成器Gemini 2.0 Flash,该功能一经上线便引起了广泛关注。与OpenAI的全模态模型相比,谷歌的这一举措无疑抢占了市场先机,尤其在动漫和漫画圈内引起了巨大反响。
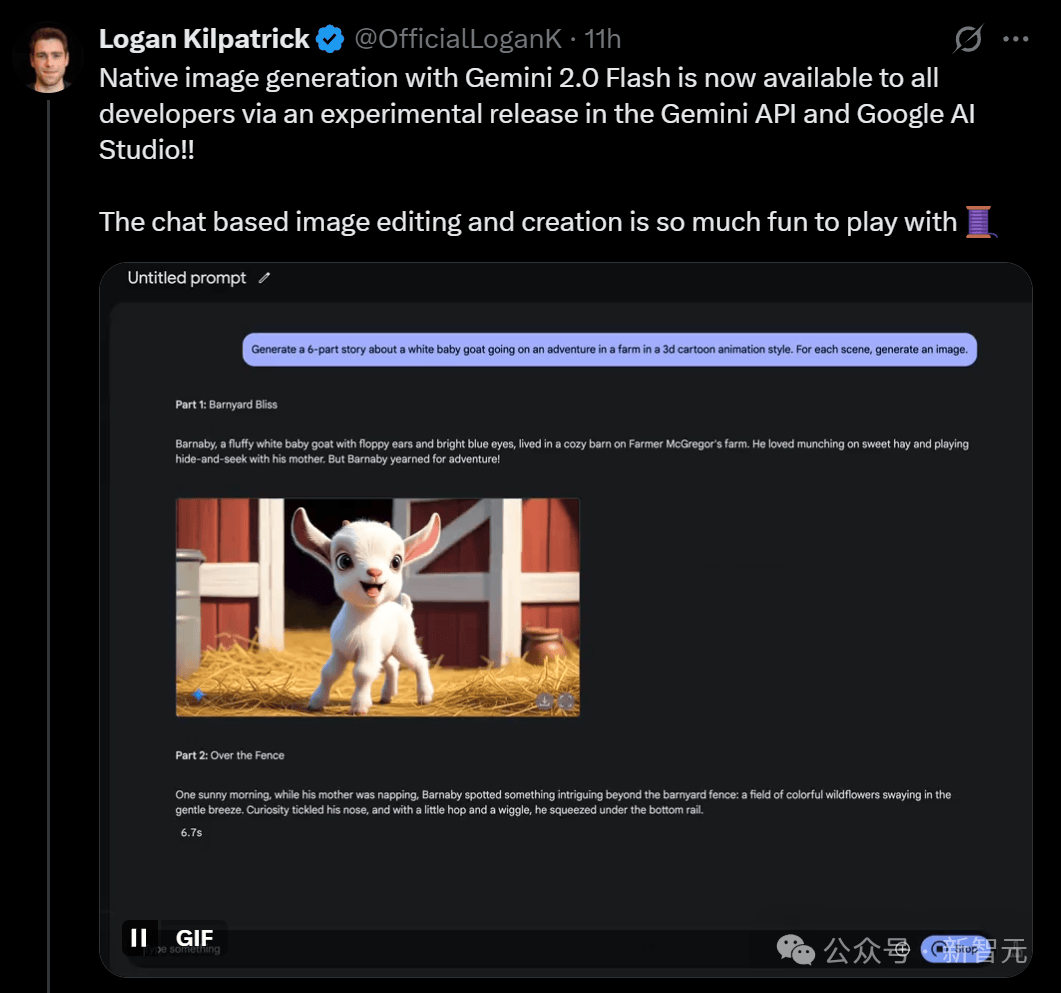
Gemini 2.0 Flash的原生图像生成功能,使得用户仅需通过自然语言提示,就能轻松生成符合上下文需求的图像。这一特性不仅极大地简化了图像创作过程,还使得图像内容更加贴近现实逻辑和文化背景。据悉,该功能的全程处理均由Gemini模型独立完成,无需调用其他辅助模型。
与传统AI生图器相比,Gemini 2.0 Flash的最大亮点在于其强大的多模态能力。它不仅能同时理解文字和图像,还能保持两者间的高度一致性。例如,用户可以在生成图像的同时,指定黑板上的文字内容,而Gemini 2.0 Flash能够准确无误地完成任务。

更令人惊叹的是,Gemini 2.0 Flash还支持对话式编辑功能。用户只需告诉模型自己的想法,模型便能在多轮对话中不断优化图像,直至用户满意为止。这种交互方式不仅提高了创作效率,还为用户提供了更多的创作自由度。
在动漫和漫画领域,Gemini 2.0 Flash的表现尤为出色。用户只需简单的提示,就能轻松生成符合自己需求的漫画分镜和角色动作。该功能还支持对漫画进行色彩填充和背景添加等操作,使得漫画创作变得更加简单快捷。

除了动漫和漫画领域外,Gemini 2.0 Flash在其他领域也展现出了强大的应用潜力。例如,在广告制作领域,用户可以利用该功能快速生成符合品牌需求的广告大片;在教育领域,教师可以利用该功能制作生动有趣的绘本和教程插图等。
当然,任何新技术在初期都难免存在一些不足。有用户反映,在某些情况下,Gemini 2.0 Flash难以输出不带文字的图像。对此,谷歌Gemini团队表示将不断改进该功能,并建议用户在使用时先以文本形式进行思考。

尽管如此,Gemini 2.0 Flash的推出无疑为AI图像生成领域带来了新的变革。它不仅提高了图像创作的效率和自由度,还为动漫、漫画、广告等多个领域的发展注入了新的活力。随着技术的不断进步和完善,相信Gemini 2.0 Flash将在未来发挥更加重要的作用。









