在探索通用人工智能(AGI)的征途上,混合专家(MoE)模型凭借其动态稀疏计算的独特优势,已成为提升大型模型推理效率的关键一环。华为团队近期推出的Pangu Pro MoE 72B模型,专为昇腾平台设计,不仅显著降低了计算成本,还在SuperCLUE榜单中,于千亿参数规模内模型中并列国内榜首。
通过一系列系统级的软硬件协同优化措施,包括高性能算子融合优化与模型原生投机算法优化,Pangu Pro MoE的推理性能实现了6至8倍的提升。在昇腾300I Duo上,单卡吞吐能力可达321 tokens/s,展现出极高的性价比;而在昇腾800I A2上,更是飙升至1528 tokens/s,充分释放了硬件的潜能,为用户带来极致的推理体验。
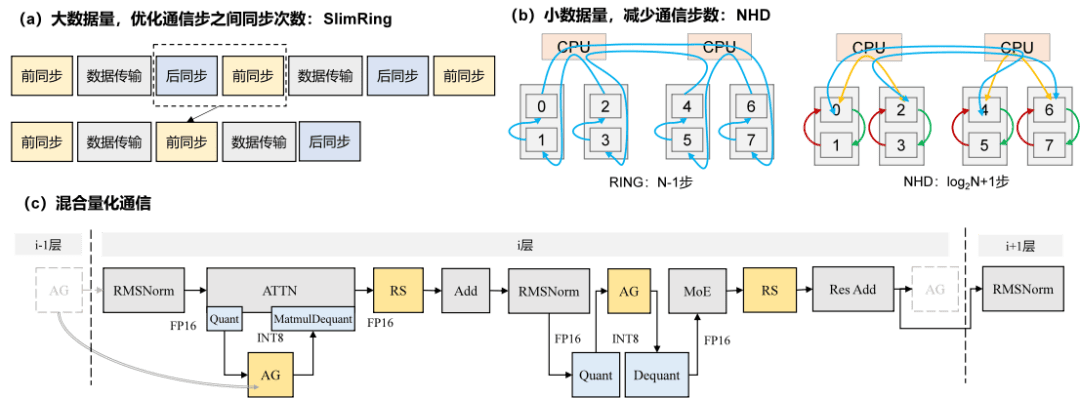
图1:H2P优化方案示意图
H2P策略还在Attention模块中引入了Reduce-Scatter替代AllReduce,避免了数据聚合操作带来的通信传输数据量膨胀问题,并通过优化AllGather的插入位置,减少了冗余向量计算。这种“专人专会”的分工方式,使得每个模块都能在最适合的并行方式下发挥最大潜能,推理效率显著提升。
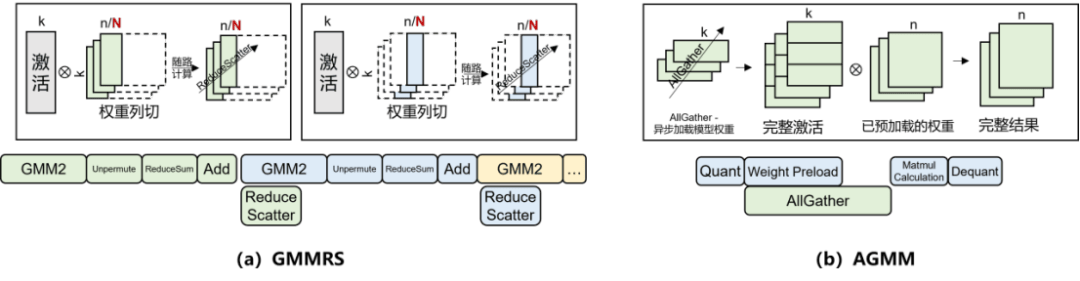
图2:DuoStream优化方案示意图
华为团队还设计了TopoComm优化方案,从静态开销和传输耗时两个方面对集合通信进行了深度优化。SlimRing算法通过合并相邻通信步的后同步与前同步操作,降低了同步次数;NHD算法则通过拓扑亲和的分级通信提高了链路有效带宽。同时,引入INT8 AllGather + FP16 Reduce-Scatter的混合量化通信策略,实现了通信数据的压缩和传输耗时的降低。
在推理过程中,计算与通信的融合也是提升效率的关键。华为团队提出了DuoStream算子级多流融合通算优化方案,实现了计算与通信的细粒度并发调度。针对Pangu Pro MoE模型中Expert模块通信占比高的问题,构建了GMMRS与AGMM两大融合策略,有效克服了通信与数据搬运和计算之间的瓶颈。
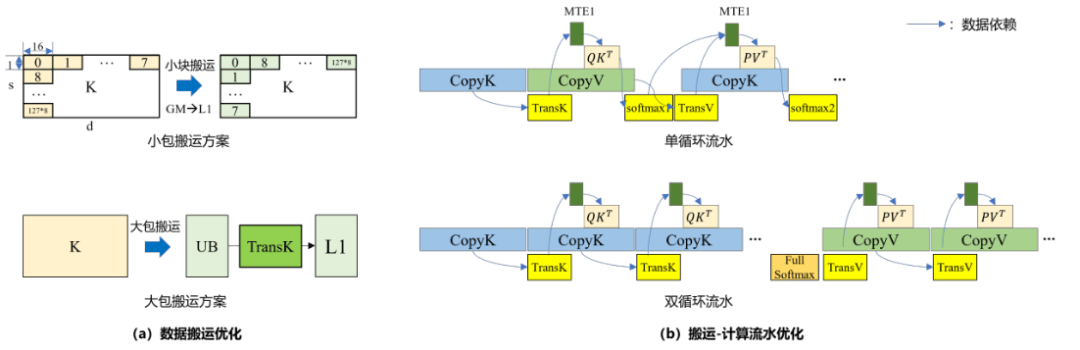
图3:MulAttention融合算子优化设计示意图
华为团队还重构了算子执行范式,打造了MulAttention和SwiftGMM两支精锐的融合算子特种部队。MulAttention算子通过构建KV大包连续搬运优化策略和KV预取流水机制,实现了Attention计算的加速。而SwiftGMM算子则通过智能分块缓存策略和动态切换GEMV与GEMM执行模式,实现了GMM计算的加速。
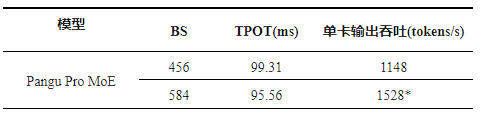
图4:昇腾800I A2服务器解码阶段推理性能测试结果
在推理算法方面,华为团队也提出了多项创新。PreMoE算法通过动态剪枝MoE模型中的专家,实现了推理吞吐的提升。TrimR算法则通过监测大模型的思考过程,避免了过度思考和欠思考的情况,降低了推理步数。SpecReason算法则利用小模型生成token序列,再由大模型进行验证,充分发挥了小模型的优势,提升了推理吞吐。
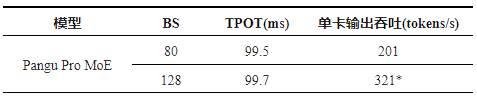
图5:昇腾300I Duo服务器解码阶段推理性能测试结果
昇腾800I A2和昇腾300I Duo两款服务器在Pangu Pro MoE模型的推理性能上均表现出色。昇腾800I A2在高并发场景下实现了1528 tokens/s的吞吐能力,而昇腾300I Duo则以其极高的性价比,在百亿级MoE模型推理中展现出卓越性能。这些成果充分展示了华为团队在模型与系统软硬协同创新方面的深厚实力,为通用大模型的规模部署和高效落地提供了坚实支撑。