在万众瞩目中,美国人工智能巨头OpenAI终于揭开了其新一代旗舰模型GPT-5的神秘面纱。然而,这场期待已久的发布并未带来预期中的震撼,反而引发了业界对于人工智能发展步入“深水区”的广泛讨论。

OpenAI的首席执行官山姆·奥特曼在发布会前的一番自嘲,称自己在GPT-5面前“一无是处”,无疑为这场发布预设了高调的背景。然而,当GPT-5真正亮相时,其表现却显得颇为平淡,更像是行业飞速迭代中的一次日常更新,而非颠覆性的突破。
GPT-5的两大技术亮点——处理多模态任务的模型能力和工具使用能力,虽然在某种程度上解决了人工智能“智能体”应用中的一些问题,但并未展现出足以甩开其他竞争对手的明显优势。这些所谓的“突破”,在业内人士看来,更像是“新瓶装旧酒”,缺乏令人眼前一亮的新意。
在“人类最后的考试”这一针对大语言模型的基准测试中,GPT-5的表现虽然比ChatGPT Agent略胜一筹,但整体成绩依然不够亮眼。截至测试时,冠军宝座已被谷歌的Gemini 2.5 Pro Preview占据,而OpenAI的o3(high)则紧随其后,位列第二。
技术瓶颈的显现,成为GPT-5难以摆脱的阴影。预训练式模型的天花板已经出现,高质量网络数据的枯竭使得大模型难以继续通过抓取互联网文本、代码库等开源资源来提升性能。同时,适用于千亿级参数的训练技巧在万亿规模上失效,导致性能倒退,这使得OpenAI不得不面对严峻的技术挑战。
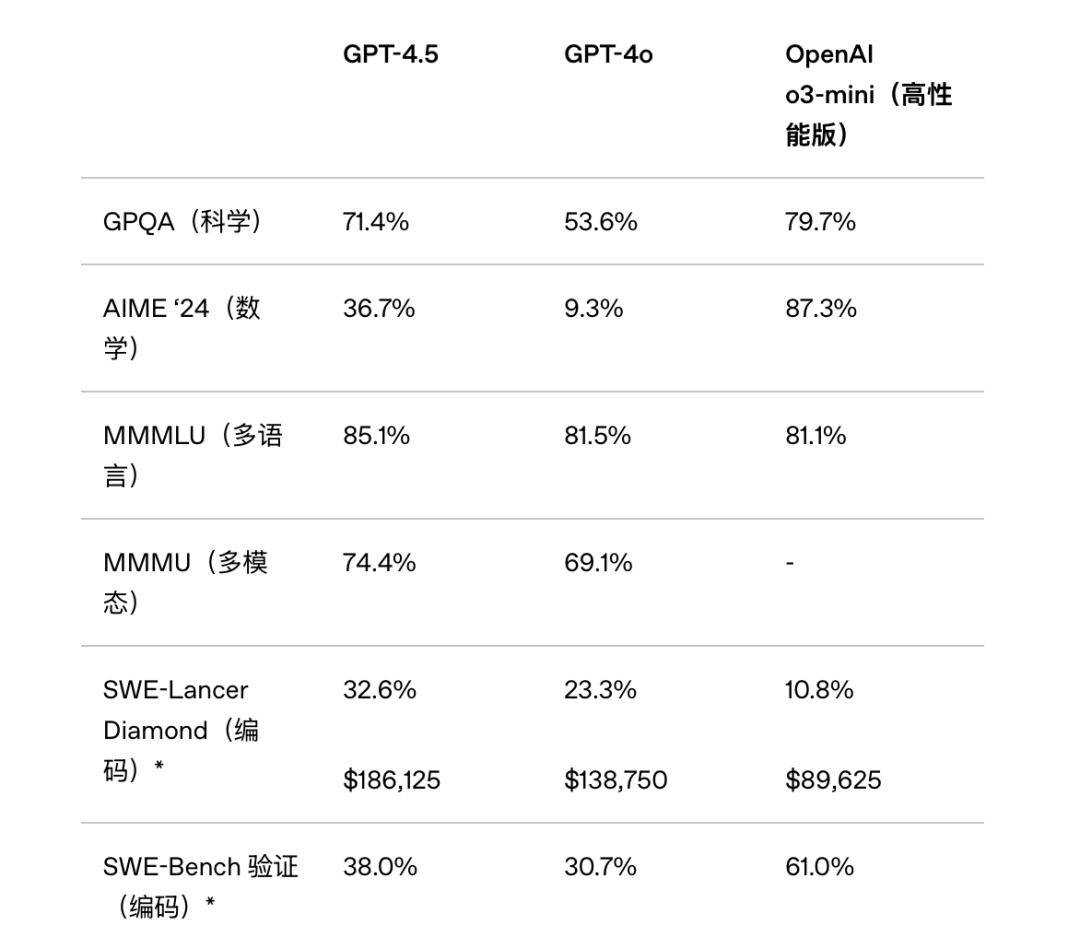
GPT-5在发布会上的一个小插曲也引发了关注:一张图表数据失真,将69.1数值的柱状图绘制得比52.8数值的还低。这一低级错误不仅暴露了OpenAI在技术细节上的疏忽,也进一步加剧了公众对其技术实力的质疑。
在竞争日益激烈的人工智能领域,OpenAI的霸主地位已经感受到了前所未有的挑战。谷歌、meta以及埃隆·马斯克的xAI等强劲对手正紧随其后,旗舰模型的实力差距仅在3个月以内。而在中国市场,阿里的Qwen系列和深度求索的DeepSeek系列等开源模型也在迅速崛起,与OpenAI的差距不断缩小。
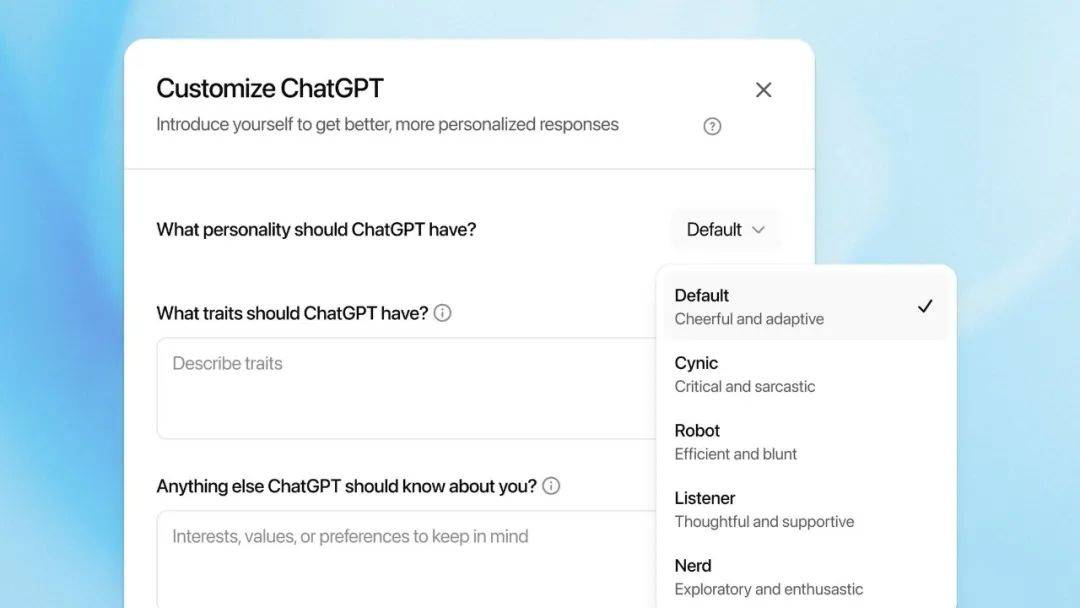
面对内忧外患,OpenAI不得不采取一系列措施来应对。为了缓解“不开源”的质疑,OpenAI在GPT-5发布前两天抢先推出了两个开源小模型。同时,为了吸引用户,OpenAI也开始拼低价、拼“辨识度”,甚至模仿竞争对手Grok 4推出了“人格化”功能,为GPT-5设置了四种不同的人格。
然而,这些举措能否帮助OpenAI摆脱当前的困境,尚需时间验证。在人工智能行业步入“深水区”的背景下,技术的渐进式优化已成为常态,资本与人才的竞争也日趋白热化。对于OpenAI而言,如何在这样的环境中保持领先地位,将是一个长期而艰巨的挑战。