腾讯混元团队携手腾讯音乐天琴实验室,近期联合发布了一项名为HunyuanVideo-Avatar的创新技术,并宣布将其开源。这项技术允许用户仅凭一张个人照片和一段音频,便能快速生成富有表情、唇形精准同步以及全身动作协调的动态视频。
HunyuanVideo-Avatar是腾讯混元视频大模型与MuseV技术深度结合的产物,具备出色的多模态理解能力。它能有效分析输入图像中的人物背景信息和音频中的情感内容,进而生成与输入高度匹配的视频片段。例如,当用户提交一张在海滩弹奏吉他的女性照片,并配以抒情音乐时,系统能自动理解并生成一段该女性在海边弹唱抒情歌曲的音乐表演视频。

在技术突破方面,HunyuanVideo-Avatar超越了传统数字人技术仅支持头部动作的局限,全面支持头肩、半身和全身三种视角模式。该技术还涵盖了赛博朋克、2D动漫、中国水墨画等多种艺术风格,并能驱动机器人、动物等多种角色,同时具备处理双人或多人互动场景的能力。
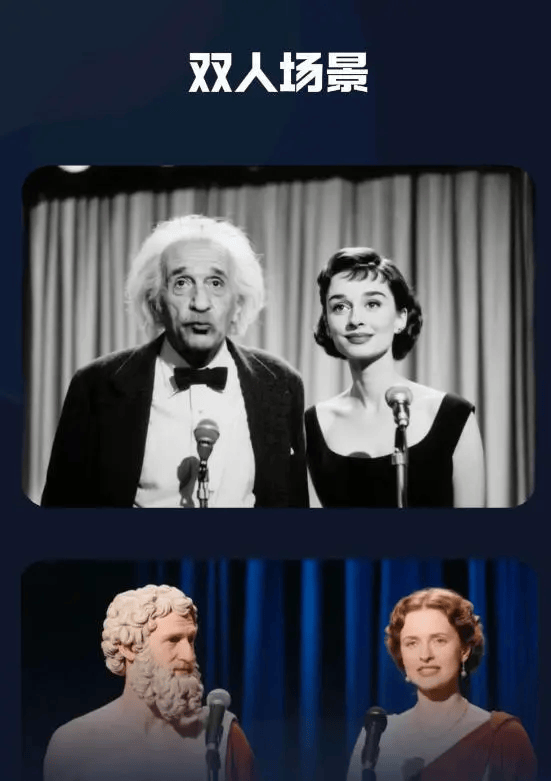
HunyuanVideo-Avatar已在腾讯音乐娱乐集团的多个核心产品中落地应用。在QQ音乐平台上,当用户播放“AI力宏”的歌曲时,AI生成的虚拟形象会实时同步演唱动作。酷狗音乐的长音频绘本功能则集成了AI虚拟人讲故事的能力,为用户带来更加丰富的听觉体验。全民K歌则推出了用户专属MV生成功能,用户只需上传个人照片,即可制作个性化的唱歌视频。
在技术架构上,HunyuanVideo-Avatar采用了多模态扩散Transformer(MM-DiT)作为核心架构,通过角色图像注入模块确保视频中人物形象的连贯性。音频情感模块能从声音和图像中提取情感特征,生成细腻的面部表情和肢体动作。对于多人场景,该技术配备了面部感知音频适配器,利用人脸掩码技术实现多角色的独立精准驱动。
据官方介绍,HunyuanVideo-Avatar在主体一致性和音画同步准确度方面已达到业内领先水平,超越了现有的开源和闭源解决方案。在画面动态性和肢体自然度方面,该技术与其他主流闭源方案处于同一技术层次。
目前,HunyuanVideo-Avatar的单主体功能已在腾讯混元官方网站开放体验,用户可通过“模型广场-混元生视频-数字人-语音驱动”的路径访问该功能。目前系统支持上传不超过14秒的音频文件,未来将逐步开放更多高级功能模块供用户使用。